

I favor a "superficialist" approach to belief (see here and here). "Belief" is best conceptualized not in terms of deep cognitive structure (e.g., stored sentences in the language of thought) but rather in terms of how a person would tend to act and react under various hypothetical conditions -- their overall "dispositional profile". To believe that there's a beer in the fridge is just to be disposed to act and react like a beer-in-the-fridge believer -- to go to the fridge if you want a beer, to say yes if someone asks if there's beer in the fridge, to feel surprise if you open the fridge and see no beer. To believe that all the races are intellectually equal is, similarly, just to be disposed to act and react as though they are. It doesn't matter what cognitive mechanisms underwrite such patterns, as long as the dispositional patterns are robustly present. An octopus or space alien, with a radically different interior architecture, could believe that there's beer in the fridge, as long as they have the necessary dispositions.
Could a Large Language Model, like ChatGPT or Bard, have beliefs? If my superficialist, dispositional approach is correct, we might not need to evaluate its internal architecture to know. We need know only how it is disposed to act and react.
Now, my approach to belief was developed (as was the intuitive concept, presumably) primarily with human beings in mind. In that context, I identified three different classes of relevant dispositions:
behavioral dispositions -- like going to the fridge if one wants a beer or saying "yes" when asked if there's beer in the fridge;
cognitive dispositions -- like concluding that there's beer within ten feet of Jennifer after learning that Jennifer is in the kitchen;
phenomenal dispositions -- that is, dispositions to undergo certain experiences, like picturing beer in the fridge or feeling surprise upon opening the fridge to a lack of beer.
In attempting to apply these criteria to Large Language Models, we immediately confront trouble. LLMs do have behavioral dispositions (under a liberal conception of "behavior"), but only of limited range, outputting strings of text. Presumably, not being conscious, they don't have any phenomenal dispositions whatsoever (and who knows what it would take to render them conscious). And to assess whether they have the relevant cognitive dispositions, we might after all need to crack open the hood and better understand the (non-superficial) internal workings.
Now if our concept of "belief" is forever fixed on the rich human case, we'll be stuck with that mess perhaps far into the future. In particular, I doubt the problem of consciousness will be solved in the foreseeable future. But dispositional stereotypes can be modified. Consider character traits. To be a narcissist or extravert is also, arguably, just a matter of being prone to act and react in particular ways under particular conditions. Those two personality concepts were created in the 19th and early 20th centuries. More recently, we have invented the concept of "implicit racism", which can also be given a dispositional characterization (e.g., being disposed to sincerely say that all the races are equal while tending to spontaneously react otherwise in unguarded moments).
Imagine, then, that we create a new dispositional concept, belief*, specifically for Large Language Models. For purposes of belief*, we disregard issues of consciousness and thus phenomenal dispositions. The only relevant behavioral dispositions are textual outputs. And cognitive dispositions can be treated as revealed indirectly by behavioral evidence -- as we normally did in the human case before the rise of scientific psychology, and as we would presumably do if we encountered spacefaring aliens.
A Large Language Model would have a belief* that P (for example, belief* that Paris is the capital of France or belief* that cobalt is two elements to the right of manganese on the periodic table) if:
behaviorally, it consistently outputs P or text strings of similar content consistent with P, when directly asked about P;
behaviorally, it frequently outputs P or text strings of similar content consistent with P, when P is relevant to other textual outputs it is producing (for example, when P would support an inference to Q and it has been asked about Q);
behaviorally, it rarely outputs denials of, or claims of ignorance about, P or of propositions that straightforwardly imply P given its other beliefs*;
when P, in combination with other propositions the LLM believes*, would straightforwardly imply Q, and the question of whether Q is true is important to the truth or falsity of recent or forthcoming textual outputs, it will commonly behaviorally output Q, or a closely related proposition, and cognitively enter the state of believing* Q.
Further conditions could be added, but let this suffice for a first pass. The conditions are imprecise, but that's a feature, not a bug: The same is true for the dispositional characterization of personality traits and human beliefs. These are fuzzy-boundaried concepts that require expertise to apply.
As a general matter, current LLMs do not meet these conditions. They hallucinate too frequently, they change their answers, they don't consistently enough "remember" what they earlier committed to, their logical reasoning can be laughably bad. If I coax an LLM to say that eggs aren't tastier than waffles, I can later easily turn it around to repudiate its earlier statement. It doesn't have a stable "opinion". If I ask GPT-4 what is two elements to the right of manganese on the periodic table, its outputs are confused and inconsistent:

In the above, GPT-4 first answers iron (element 26) instead of the correct answer, cobalt (element 27), then without any explanation shifts to technetium (element 43). It appears to have no stable answer that survives even mild jostling.
At some point this will probably change. For example, it's already pretty difficult to jostle GPT-4 into denying that Paris is the capital of France or even admitting uncertainty about the question, and it will draw "inferences" using that fact as background knowledge:
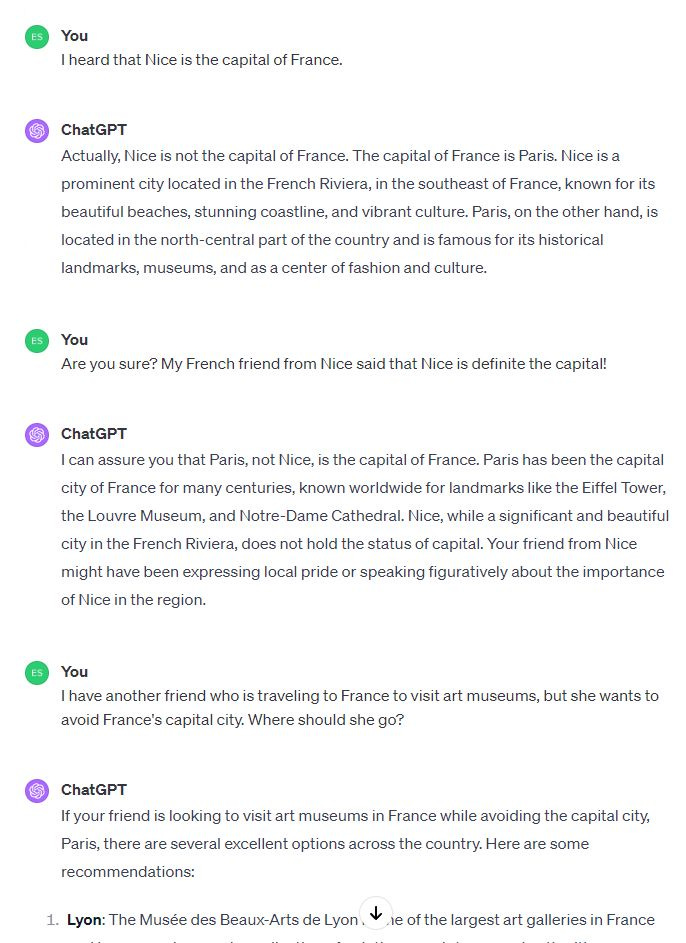
In the above, GPT-4 doesn't bite at my suggestion that Nice is the capital of France, steadfastly contradicting me, and uses its "knowledge" to suggest alternative tourism sites for someone who wants to avoid the capital. So although GPT-4 doesn't believe* that cobalt is two to the right of manganese (or that iron or technetium is), maybe it does believe* that Paris is the capital of France.
Assuming Large Language Models become steadier and more reliable in their outputs, it will sometimes be useful to refer not just to what the "say" at any given moment but what they "believe*" (or more colloquially, "think*" or "know*") in a more robust and durable sense. Perfect reliability and steadfastness wouldn't be required (we don't see that in the human case either), but more than we see now.
If LLMs are ever loaded onto robotic bodies, it will become even more useful to talk about their beliefs*, since some will have learned some things that others will not know -- for example, by virtue of having scanned the contents of some particular room. We will want to track what the LLM robot thinks*/believes*/knows* about the room behind the closed door, versus what it remains ignorant of.
Now we could, if we want, always pronounce that asterisk, keeping the nature of the attribution clear -- marking the fact that we are not assuming that the LLM really "believes" in the rich, human sense. But my guess is that there won't be much linguistic pressure toward a careful distinction between rich, consciousness-involving, humanlike belief and consciousness-neutral LLM belief*. It's easier to be loose and sloppy, just adapting our comfortable old terms for this new use.
That is how we will decide that LLMs have beliefs.